On se lance enfin dans l’observation d’une transcription par Transkribus.
Je travaille sur l’acte de 1816, Wallon-Cappel, en français, celui qui nous a servi d’exemple dans les articles L pour détecter les Lignes avant de déchiffrer et N Nouvel essai de détection de ligne sur un acte de naissance de 1816.
On a vu que le modèle de détection de lignes s’en sort plutôt bien, avec un problème dans la zone de signature, mais cela ne va pas trop nous gêner.
J’ai essayé deux modèles, je vous présente en détails celui qui marche le mieux.
Tuto rapide Transkribus
- https://app.transkribus.eu
- il faut avoir un compte et des crédits. A la création du compte, on a un crédit de 500, ce qui permet de faire 500 transcriptions
- il faut avoir chargé le document dans Transkribus (bouton « Upload File » car mon interface s’est remise en anglais)
- sélectionner le document, puis bouton « Recognize »
- voir capture d’écran, il faut sélectionner un modèle en s’aidant des filtres. Je choisis « handwritten » (manuscrit), French (français), entre le 18ème et 19ème siècle (c’est la barre sous « centuries »).
- Sélectionner un modèle, et cliquer sur « Start recognition »

- Ça va travailler en arrière-plan. Pour voir où ça en est, il faut aller dans le menu « Jobs ». De là, on voit tout ce que Transkribus a fait pour nous en arrière plan. Sur cet exemple, toutes mes tâches sont en état « Finished », tout est fait. C’est très rapide, de l’ordre de une minute pour un document dans mon essai.

Résultats avec le modèle « The Text Titan 1 »
Voilà le résultat
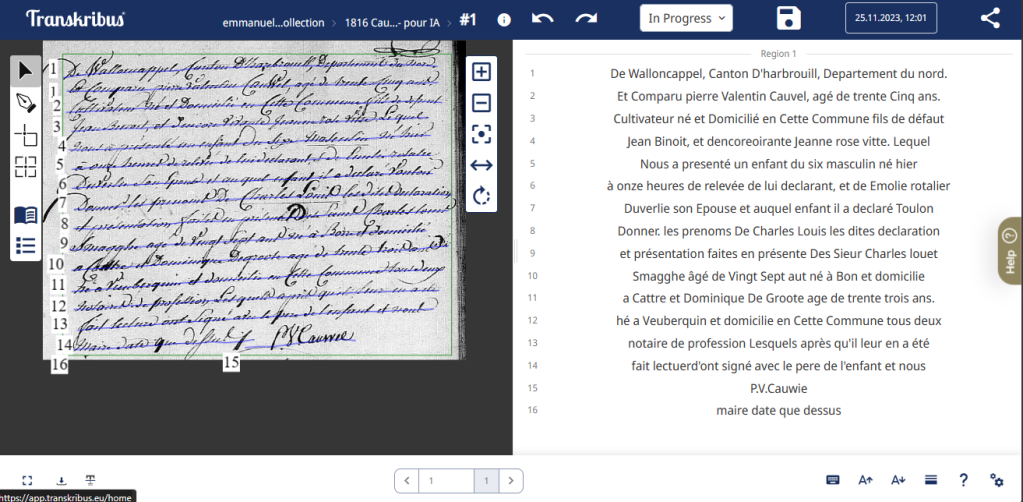
En première impression, la transcription donne quelque chose de très lisible. Quelle en est la précision? Pour l’évaluer, j’ai compté le nombre de mots dans l’acte d’origine : 132. Puis j’ai compté le nombre de mots erronés dans la transcription : 19. Cela fait un pourcentage d’erreurs de 14%, ou 86% d’exactitude
Ensuite, j’ai analysé sur quelles catégories de mots la transcription est imprécise. Voilà mes catégories:
- les noms de lieu (ou toponymes)
- les noms de familles (patronymes)
- les prénoms
- et les mots stéréotypés, je ne sais pas comment les appeler, les mots qui reviennent très souvent dans un type d’acte donné et que les humains reconnaissent facilement dès qu’ils ont quelques modèles. Je vais les appelé ‘mots spécifiques au type de document »
| Total | Erreurs | % | Liste | |
| Tous mots confondus | 132 | 19 | 14% | |
| Noms de lieux | 6 | 4 | 67% | Harbrouill pour Hazebrouck Cattre pour Castre Bon pour Borre Veuberquin pour Vieu[x]berquin |
| Noms de famille | 6 | 3 | 50% | Cauvel et Cauwie pour CAUWEL Vitte pour VITSE |
| Prénoms | 13 | 4 | 31% | Binoit pour Benoit Emolie Rotalier pour Emilie Rosalie Louet pour Louis |
| Mots spécifiques aux actes de naissance | beaucoup | 7 | peu | encore vivante, défunt, ans, sexe, lecture, né, vouloir (dans expression « vouloir donner ») |
On voit donc que le modèle IA se trompe sur les lieux deux fois sur trois, sur les patronymes une fois sur deux et sur les prénoms une fois sur trois. Il se trompe aussi sur les noms spécifiques aux actes de naissance, mais je n’ai pas quantifié.
On a l’impression que ce problème sur ces quatre catégories de mots est relativement facile à résoudre. Voici comment les humains les résolvent, et ce qu’il faudrait aux IA pour les résoudre.
| Humains | Intelligence artificielle | |
| noms de lieux | liste de noms de lieux, sélection par proximité géographique avec le lieu de l’acte ou d’autres lieux mentionnés dans l’acte | déjà, arriver à identifier qu’un mot est un nom de lieu; accéder à des ressources sur les noms de lieu |
| noms de famille | connaissances des noms de familles présents dans la zone géographique; rapprochement avec des noms de famille déjà présents dans l’acte, ou dans le registre (consultation des tables décennales par exemple) | idem qu’avec les noms de lieu, mais pour les patronymes |
| prénoms | prénoms présents sur la zone géographique à l’époque considérée ; prénoms déjà présents dans le même registre (tables décennales également) | idem qu’avec les noms de lieu et les patronymes, mais avec les prénoms. C’est plus simple peut-être car il me semble que le stock de prénoms est beaucoup, beaucoup plus limité. |
| mots spécifiques au type d’acte | prendre modèle sur les autres actes du même registre | le modèle IA doit être entrainée avec des documents de similaires à ceux qu’on veut déchiffrer |
Notez que ce tableau vient de ma réflexion immédiate là, à chaud. Néanmoins, il y a un parallèle avec l’article de recherche dont je rends compte ici : Finir l’expérience IA et cartes : compte rendu d’un article de recherche. Une des conclusions des chercheurs est (traduit et interprété par moi)
Les modèles sont limités car ils n’ont pas accès aux données à mettre sur les cartes [ je suppose qu’il s’agirait, exemple super simple, de listes de communes géolocalisées ]. L’intégration de modules de recherche et de collecte de données est incontournable. En effet, les IA entraînées juste à partir d’exemple de cartes existantes ne peuvent pas produire de carte représentant des phénomènes spécifiques, ou des statistiques
Transkribus French model 1
Bien moins bonnes performances que l’autre. mettre le tableau, pas de calcul d’erreurs
In Progress In Progress Done Ground Truth Final 25.11.2023, 12:51
Ma conclusion
Très forte sensibilité au modèle ; grosse grosse différence ; comparer les modèles, pas bien documentés, la différence = nombre de documents?
Erreurs sur les mots stéréotypés, noms propres, prénoms, lieux. Ce qui me fait penser qu’en entraînant un modèle sur un petit corpus donné, l’IA peut vraiment se débrouiller. Là on a entrainé sur qq chose de vraiment gros et général, on a bien l’impression qu’on apprend à qq un à lire uniquement à partir des registres de Wallon Cappel, il va très bien s’en sortir. par contre, pas en généralisation.
Pour accélérer la lecture d’un corpus je pense que ça marche très bien: tout un registre, puis lecture humaine de qq un, qui saura survivre aux approximations et reconstituer les prénoms, noms et toponymes sans s’émouvoir. reprendre la correction acte par acte de ceux qui posent problème
2- les subtilités de détection de ligne sont diaboliques
