(si vous cherchez un article avec des conclusions, passez votre chemin et revenez plus tard)
Dans l’article Indexer 0,016% des matricules Napoléoniens, j’expliquais que l’indexation des registres militaire des armées de Napoléon, ça m’a lassée et donné envie de regarder ce que peut l’IA. Il s’agissait de faire ça (des centaines de milliers de fois) :

Le format du registre
Le registre est un formulaire imprimé, rempli à la main. Sa structure est toujours identique. Cela se présente comme une table de 6 lignes, 5 colonnes. Une ligne = une personne

Sur chaque ligne, on a les informations à relever : le nom, le nom des parents, la date et lieu de naissance. Et d’autres informations qui ne sont pas relevées dans le cadre de ce projet d’indexation. D’ailleurs je trouverais intéressant d’indexer la profession.

Il faut faire détecter un tableau
Je pense qu’on ne va s’en sortir que si la détection de mise en page arrive bien à identifier un tableau, ligne par ligne d’abord, case par case ensuite. Le contenu qui nous intéresse est dans les premières cases de chaque colonne. C’est juste une partie de cette case qui nous intéresse, pas tout.
Mon idée, c’est de ne pas apprendre à l’IA à tout lire, ça ne sert à rien, ça prend de la ressource. Je ne sais pas si j’ai raison de penser ça, peut-être qu’avec les IA il ne faut pas trop réfléchir en amont, balancer des gros volumes de données, et voir comment ça se débrouille.
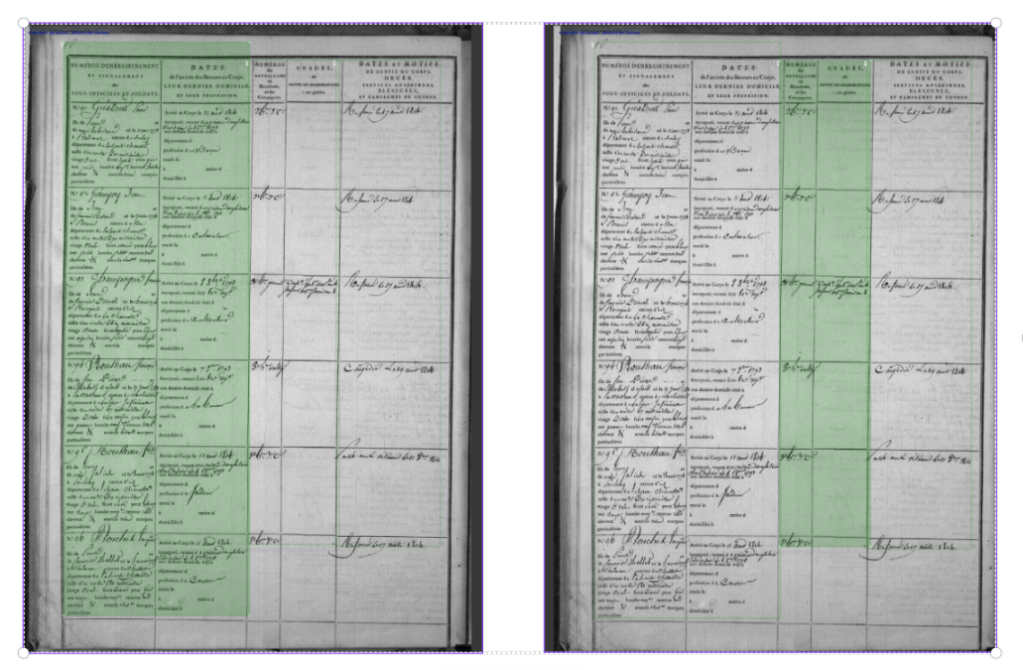
Toujours est-il que pour le moment, je voudrais que l’IA sache faire une détection de mise en page comme ça : d’abord, en rouge, une case par bonhomme. Puis, plus tard, dans chaque case, 5 lignes et c’est tout. Je vous les ai soulignées en vert. Mais on n’en est pas encore là.

Résultat avec Transkribus
Je vais faire court : quasi rien.
J’ai testé les détections de ligne standard : Universal Lines, Mixed Lines orientation, Horizontal Lines orientation. Je n’ai pas réussi à avoir des détection de case (cellule) individuelle
Ma conclusion
Je pense qu’il y a déjà moyen d’utiliser les modèles de Transkribus pour lire des documents présentés sous forme de tableau. C’est peut-être un peu compliqué, il doit falloir trouver les modèles à entraîner. Faudrait trouver des exemples et des retours d’expérience.
Mais également, Transkribus a annoncé tout récemment (octobre 2023) le lancement de « Table modèles » et de « Field modèles », encore en phase de tests. Il s’agit donc d’une affaire à suivre !
Annonce la plus récente
Introducing Table Models – Trainable Layout AI in Transkribus – READ-COOP (readcoop.eu) – annonce de fin octobre 2023 sur l’introduction de modèles de tables, pas encore disponibles sauf en version beta (https://beta.transkribus.eu/). J’ai essayé de tester, avec divers problèmes qui me bloquent pour l’instant.
Autres ressources pas encore exploitées

Très clair et pédagogique. J’ai tout compris !!!
J’aimeJ’aime